(Part 2) Reducing the Cost of Running a Personal k8s Cluster: Volumes and Load Balancers

In the previous post in this series, we showed how utilizing Spot Instances and Reserved Instances reduces the annual bill for running our Kubernetes cluster from ~2K to ~1.2K. In this post, we’ll pursue cost reduction for storage and networking resources, our final two prominent, unoptimized costs.1 Our quick calculations from the first post in this series show, that with the default Kops configuration, we pay ~$360 annually for EBS (storage) and ~$216 annually for ELBs (networking), for an annual total of just over $500.
These costs are significant. Even more troubling, our current Kubernetes implementation has us utilizing an unique ELB for each service, meaning our network resources costs will grow linearly with the number of services running on our cluster. Our goal in this blog post is to show how we can reduce, or at the very least cap, our expenditures for storage and networking resources on our Kubernetes cluster.
Optimizing EBS volumes
We pay for EBS in two different ways with our Kubernetes cluster.
Types of EBS Costs: Root Volumes
First, we pay for the EBS volumes which Kops attaches directly to the master and nodes in our cluster. We call these the root volumes. The default root volume size for masters is 64GB, and the default root volume size for the node is 128GB. Altogether, Kops allocated 320GB. At $.10 per GB-month, when using gp2 volumes, we pay $32 a month for the root volumes mounted directly to our master and nodes.
I’m a little surprised that Kops uses such a large default volume size, because
ssh’ing into the host and running a quick df -h showed our hosts vastly
over-provisioned with respect to storage.
We immediately reduced the rootVolumeSize for both the master and the nodes to
30GB and 64GB respectively, using the method described in the Kops
documentation.
We now pay ~$15 a month, instead of $32, for our hosts’ EBS volumes, cutting our EBS bill in half for a savings of around $180 annually.
Monitoring and Alerting on Root Volume Provisioning
We can again use a combination of Prometheus and Grafana to verify we did not
under-provision our instances with respect to storage when we shrunk the
rootVolumeSize.
To do so, we start by running the Prometheus Node Exporter as a DaemonSet on our cluster. We have not yet discussed DaemonSets, but they can be thought of as similar to Deployments, except instead of ensuring our cluster is running n copies of pod, DaemonSets ensure that all nodes run an instance of the specified Pod. Running node monitoring daemons, such as Node Exporter, is one of the most common uses of DaemonSets.
The manifest for our Node Exporter DaemonSet can be seen below. We heavily based it on the manifest defined in the CoreOS Prometheus Operator’s kube-prometheus manifests.
Similar to with a Deployment, we define a Service for the Node Exporter, which provides us a single point of access for all the NodeExporter pods running on the different nodes.
You can see all of the manifest files in my personal-k8s repo.
We can configure Prometheus to begin collecting these metrics by adding a NodeExporter ServiceMonitor, as is included in the manifest below.
Node Exporter gives us two very useful metrics: node_filesystem_free_bytes and
node_filesystem_size_bytes. We can use the query below to show the amount of
available disk space for each instance’s root volume.
min by(device, instance)(node_filesystem_free_bytes{device=~"/dev/.*"}) /
min by(device, instance)(node_filesystem_size_bytes{device=~"/dev/.*"})
As we show below, we can also graph this expression on Grafana, which gives us insight into available disk space on the root volumes.
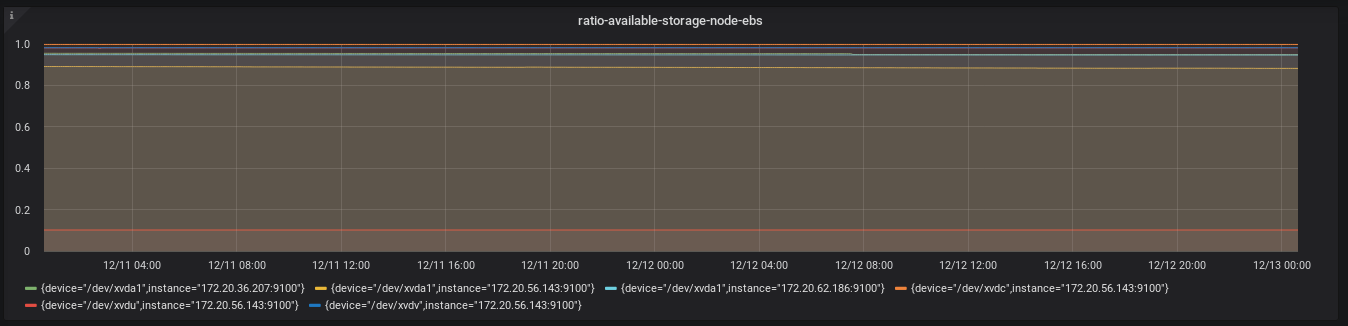
We can also add an alert for whenever we have less than X% of available disk space on our partition.
Our initial examination of these graphs shows that even after cutting the default Kops root volume size by over 50%, we’re still over-provisioning with respect to storage. When we analyze resource usage in our cluster as part of our regularly scheduled review, we may decide to shrink the root volumes even more. For now, we feel confident in our decision to decrease the root volume size.
Types of EBS Costs: PersistentVolumes
We also pay for EBS volumes when we request storage via a PersistentVolumeClaim. Essentially, PersistentVolumes are a way for pods to request persistent storage, such as AWS EBS volumes. Currently, only Prometheus requires us to save state, so Prometheus is our only application making use of PersistentVolumes.
As can be seen below, we only request 20GB for each Prometheus pod, for a total of 40GB. Again, at $.10 per GB-month, we are only paying $4 a month for this persistent storage, which feels fairly negligible.
Monitoring and Alerting on PersistentVolume Provisioning
We can copy much of our work around root volume alerting and monitoring to
PersistentVolume alerting and monitoring. Literally, the only difference is that
instead of the node_filesystem_(free|size)_bytes metrics, we utilize the
kubelet_volume_stats_(available|capacity)_bytes metrics. We can use the query
below to show the amount of available disk space on Pods’ Persistent Volumes.
min by(persistentvolumeclaim)(kubelet_volume_stats_available_bytes) /
min by(persistentvolumeclaim)(kubelet_volume_stats_capacity_bytes)
We can graph this expression on Grafana, giving us insight into historical available disk space.
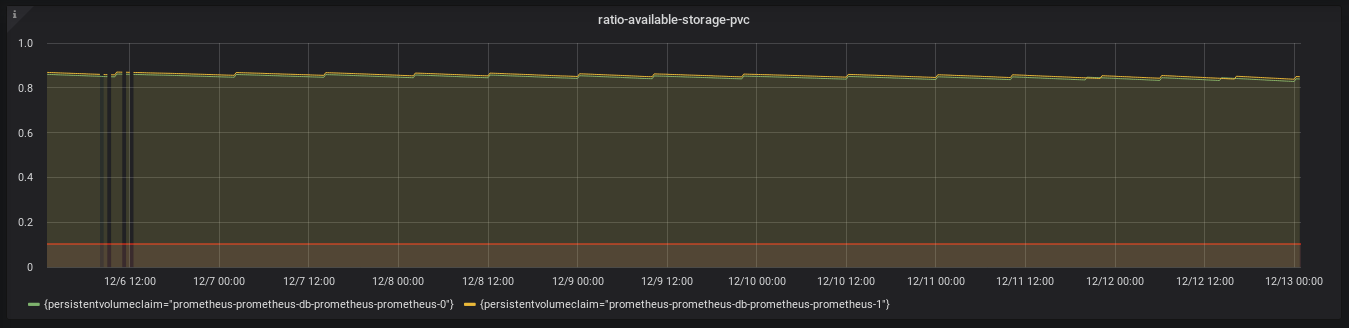
We also add an alert for whenever we have less than X% of available disk on our Persistent Volume.
With this alert, we can be confident in our non-costly allocation of 20GB of persistent storage to our Prometheus pods.
Optimizing ELB load balancers
We now turn to our ELB, for which we pay $18 a month, or $216 annually.
Our Kubernetes cluster needs an ELB whenever we want to make an application running on our Kubernetes cluster publicly available.2 Currently, only our blog is publicly available, meaning we only pay for the single ELB.
However, over time, we will wish to run more publicly available applications. We’d like our ELB expenditures to not grow linearly, as ELBs could quickly become the most expensive component of our cluster. We’d like a way to ensure that no matter how many public facing applications we run, our cluster will only have one ELB.
Fortunately, the Kubernetes Ingress resource solves this issue exactly. An Ingress exposes HTTP(s) routes from outside the cluster to internal services. Most importantly, it allows us to trade multiple services each with their own ELB for one Ingress with one ELB which routes to the correct services based on the HTTP(s) route.
We will implement an Ingress for our cluster as soon as we have another service we want to expose publicly, Our efforts to do so are captured in this ticket, and there will be a blog post describing the implementation after it’s complete.
We can now be confident that our ELB expenditures will stay capped at $18 for our Kubernetes cluster’s entire lifecycle.
Wrapping Up
With our examination of storage and networking resources complete, we have examined all the individual costs making up our Kubernetes cluster. When possible (EC2 and EBS), we reduced costs and when not possible (ELB), we ensured costs will not grow linearly with the number of applications running on our cluster.
In the next, and final, post in this series, we’ll wrap up our cost reduction efforts and discuss our total savings. Additionally, we’ll discuss additional avenues we could pursue for further cost reductions and how we plan to ensure we are remain vigilant about cluster costs over the coming months.
1. We also pay for S3 storage for our Kops configuration and Route53 entries for DNS, but these costs are negligible.
2. Our blog service is publicly available because the Service specifies a LoadBalancer as its type. When the Service type is LoadBalancer, Kubernetes will allocate a publicly facing load balancer on the cloud provider on which the cluster is running. Since we are using AWS as our cloud provider, it allocates an ELB.